Feature Descriptors
Table of Contents:
Local Image Features
Chapter 4 of the textbook focuses on points, patches, edges, lines In video, can just track the points over local neighborhood – search for corresponding location in subsequent images Other scenario – viewpoints are different enough that you cannot just search a local neighborhood Chapters 6-7 will use the information from Chapter 4 Stitching will also need features Stereo calibration will also need features Local features used to be used for object recognition High Level Idea (1) the ability to identify salient points (“features” or “landmarks”) inside each image to track,and (2) the ability to find potential correspondences between these salient points across different images (in order to track them), and (3) the ability to identify and discard incorrect correspondences
Timeline – most central parts of computer vision research Question: why might these be useful? Main idea is we wish to match features Why? Image stitching, camera calibration, image registration, Image database retrieval, structure from motion, by understanding 2d projections of 3d points, and we understand the geometry of projection very well, and by understanding which 2d points correspond to identical 3d points, we can actually solve for 3d points, giving a 3d point cloud as structure, in a least-squares sense
Moravec Operator
Hans Moravec [1] defines a corner to be a point with low self-similarity. The algorithm tests each pixel in the image to see if a corner is present, by considering how similar a patch centered on the pixel is to nearby, largely overlapping patches. The similarity is measured by taking the sum of squared differences (SSD) between the corresponding pixels of two patches. A lower number indicates more similarity. Look for local maxima The corner strength is defined as the smallest SSD between the patch and its neighbours if this number is high, then the variation along all shifts is either equal to it or larger than it, so capturing that all nearby patches look different. Measure intensity variation at (x,y) by shifting a small window (3x3 or 5x5) by one pixel in each of the eight principle directions (horizontally, vertically, and four diagonals). The “cornerness” of a pixel is the minimum intensity variation found over the eight shift directions: • Use a window surrounding each pixel as its own matching template • Tests local autocorrelation of the image: – SSD = Sum of Squared Differences • Good matches in any direction • Flat image region • Good matches in only one direction • Linear feature or edge • No good matches in any direction • Distinctive point feature • Corner point
Hans Moravec’s Stanford Cart, 1960
Looks like an absolute piece of junk. Car battery, 4, bicycle wheels The Stanford Cart used a single black and white camera with a 1-Hz frame rate. It could follow an unbroken white line on a road for about 15 meters before breaking trac developed the first stereo vision system for a mobile robot. Using a modified Cart, he obtained stereo images by moving a black and white video camera side to side to create a stereo baseline. Like human eye research platform for studying the problem of controlling a Moon rover from Earth The Cart moved 1 m every 10 to 15 min A subroutine called the Interest Operator was applied to one of these pictures. Another routine called the Correlator looked for these same regions in the other frames At each pause on its computer-controlled itinerary, the Cart slid its camera from left to right on a 52-cm track, taking nine pictures at precise 6.5-cm intervals. Po Find clouds of features on an object, don’t collide with it Human eye baseline, distance between the two cameras, is around 5-7 centimeters Harris Theorem: If A is an n × n matrix, then the sum of the n eigenvalues of A is the trace of A and the product of the n eigenvalues is the determinant of A. Flat region: no change in all directions Edge: no change along the edge direction Corner: significant change in all directions. shifting a window in any directionshould give a large change in intensity. Should easily recognize the point bylooking through a small window
Repeatability
Why repeatable? Add that there is no way to get a match if you don’t repeat the Keypoint in other image. Not optional to be repeatable. Most important property. If you see the same image content/same pattern, you must fire in the same location. Want it to be repeatable! Can’t have a match if your keypoints aren’t even in repeatable locations
Deep Keypoints
TILDE
- Find webcam images (same point of view, different seasons, different times of day)
- Identify in these images a set of locations that we think can be found consistently over the different imaging conditions.
- To collect a training set of positive samples, we first detect keypoints independently in each image of this dataset using SIFT
- Iterate over the detected keypoints, starting with the keypoints with the smallest scale.
- If a keypoint is detected at about the same location in most of the images from the same webcam, its location is likely to be a good candidate to learn.
- The set of positive samples is then made of the patches from all the images, including the ones where the keypoint was not detected, and centered on the average location of the detections.
- Learn 96 linear filters per each sequence
- Piece-wise Linear Regressor
- How can we define a descriptor vector for a keypoint? Sparse correspondences (it is not per every single pixel) At a keypoint, all we have is a single color intensity, which can easily belong to any other object. Easy to make mistakes What is a feature? Amir Zamir slide Think of 2d case. 2d vectors. Want them to lie close by each other. L2 norm/Euclidean distance between these vectors. So that semantic/content similarity is related to proximity in high-dimensional space Two species of fish What is the right feature that makes the solution transparent? Weight, a single number “Solving a problem simply means representing it so as to make the solution transparent.” - Herbert Simon, Sciences of the Artificial Simple error metrics, such as the sum of squared differences between patches A scaled and oriented patch around the detected point can be extracted and used to form a feature descriptor Extracting a local scale, orientation, or affine frame estimate and then using this to resample the patch before forming the feature descriptor is thus usually preferable Using histograms – Estimate some statistics of the patch. Then search for other patches with similar statistics (Histogram is a discrete estimate of the probability distribution of some random variable). Here, random variable is the grayscale intensity of any pixel, and it can take on 256 values [0,255], and we plot the counts of each Histogram of grayscale values
Can treat histograms as vectors, think of 2d vectors, and find similarity betwen two vectors by distance between them , L2 norm How do images change? a transformation could take the form of scene illumination, blur in video camera viewpoint changes. Camera viewpoint changes could take the form of scale changes or a rotation. Want a feature vector that is not too large, because longer vectors will mean more computation when matching and finding nearest neighbors Many of these lack a strong mathematical formulation like we saw on Monday, but are somewhat ad-hoc
[Lowe, SIFT, 1999]
Use image gradient change in the value of a quantity (as temperature, pressure, or concentration) with change in a given variable and especially per unit on a linear scale. Sobel Forward, central difference, grayscale intensity centered at one pixel, above and below, left and righ Derivative is rate of change: that is, the amount by which a function is changing at one given point The gradient is the vector formed by the partial derivatives of a scalar function Originally designed to use local features for object recognition (1999) h transforms an image into a large collection of local feature vectors, Template matching infeasible becuase of variation in object rotation, scale, illumination, and 3D pose we used 8 orientation planes, Preliminary paper Store the SIFT keys for sample images and then identify matching keys from new images
Lowe 2004 Scale-Invariant feature (SIFT)
53k citations, refined version. Now states: “perform reliable matching between different views of an object or scene” Can mix and match the detector: DOG for detecting blobs: The input image is first convolved with the Gaussian function using = p 2 to give an image A. This is then repeated a second time with a further incremental smoothing of = p 2 to give a new image, B, which now has an effective smoothing of = 2. The difference of Gaussian function is obtained by subtracting image B from A, resulting in a ratio of 2=p 2 = p 2 between the two Gaussians.



Compute image gradient magnitude and gradient orientation at every pixel This is norm of L2 norm of two numbers Arctangent, a mathematical function that is the inverse of the tangent function, atan2, arctan2
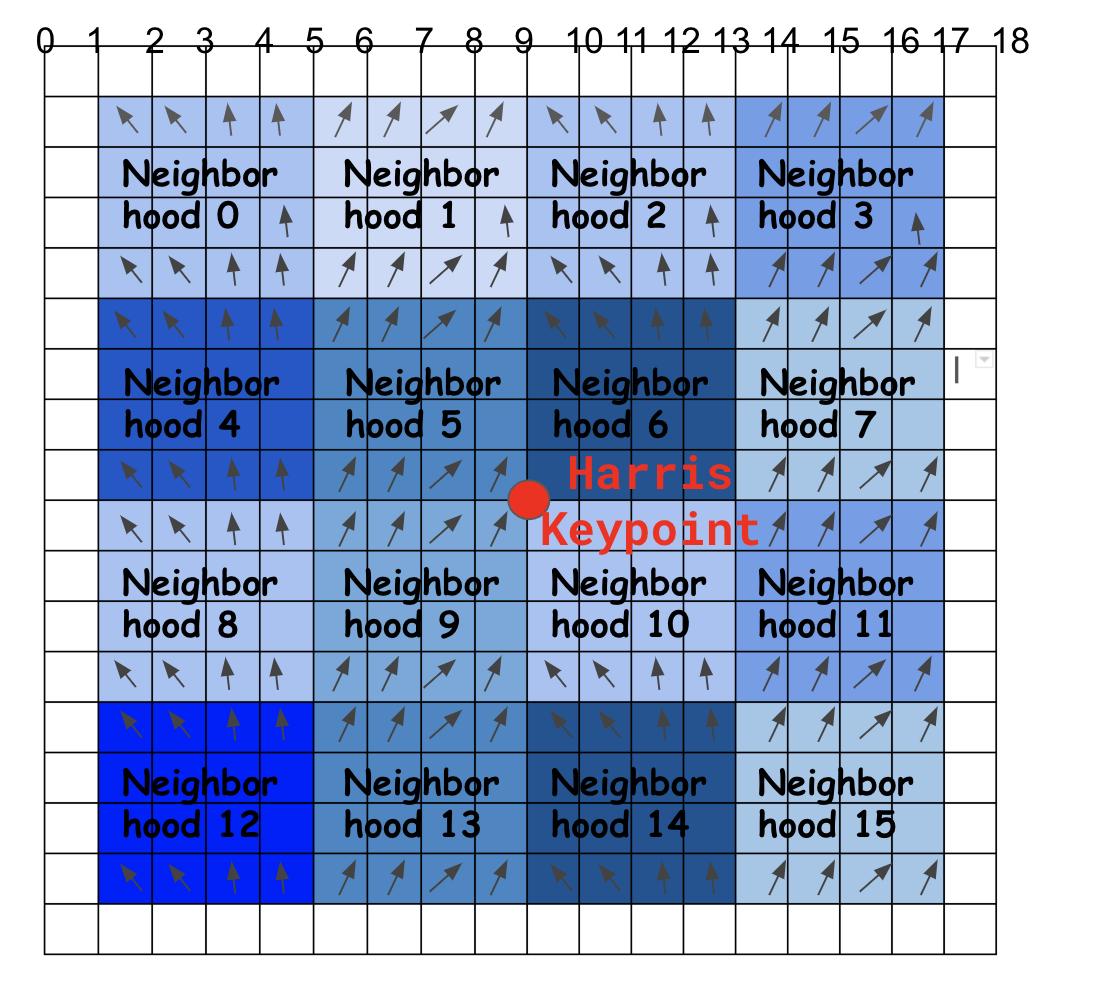
SIFT feature is not just a keypoint (x,y) location in the image. Feature also includes a scale estimate and an orientation estimate Algorithm: Step 1: Take 16x16 square window around detected interest point (8x8 window and 2x2 grid shown below for simplicity) Compute x and y partial derivatives Compute the gradient magnitude and orientation at each pixel Step 2: angle of the gradient for each pixel Step 3: threshold gradient magnitude y thresholding the values in the unit feature vector to each be no larger than 0.2, Step 4: Create histogram of surviving edge orientations (8 bins) ( length of each arrow corresponding to the sum of the gradient magnitudes near that direction within the region.) Step 5: Divide the 16x16 window into a 4x4 grid of cells Step 6: Spread out among 2 closest bins, Spread out to 4 nearest subgrids (using trilinear interpolation. It is important to avoid all boundary affects in which the descriptor abruptly changes as a sample shifts smoothly from being within one histogram to another or from one orientation to anothe trilinear interpolation is used to distribute the value of each gradient sample into adjacent histogram bins Step 7: Compute an orientation histogram for each subgrid cell Step 8: 16 cells * 8 orientations = 128 dimensional descriptor Make it rotationally invariant! Need a canonical orientation for every patch We need orientation normalization. To find the dominant orientation, compute orientation histogram with 360 degrees split into 36 bins, detect peaks in this orientation histogram. then figure out which is the up direction
Translation invariance You can shift over by 16 pixels, and you’ll get the same descriptor in the new location Scale Invariance: Or whole image: e image is rotated by 15 degrees, scaled by a factor of 0.9, and stretched by a factor of 1.1 in the horizontal direction Partially invariant to illumination changes: Could add 50 to all pixels, and barring overflow about 255, the x,y gradients would be identical Totally brightness invariant (add constant to pixels) Also contrast invariant, as long as now overflow (multiply pixels by constant) Gradient values also all get scaled by a constant If you divide all gradients by that same constant, you would get the same image gradients, leading to same To obtain brightness invariance, the SIFT descriptor is normalized to unit sum 128-dim vector normalized to 1 PLEASE DISCUSS WITH YOUR NEIGHBOR: WHAT ARE THE DISADVANTAGES OF THIS SIFT METHOD SIFT: lossy summary of this data. Very good image descriptor SIFTNet
Speeded Up Robust Features (SURF) Paper, integral image, box filters [Bay, ECCV’06], [Cornelis, CVGPU’08]
New detector and a new descriptor, fast approximations of Harris and SIFT ideas Harris corners are not scale-invariant SURF is based on Hessian matrix he determinant of the Hessian matrix is used as a measure of local change around the point and points are chosen where this determinant is maximal Gaussian second order derivatives Take derivative of Gaussian in each direction Then take derivative again Descriptor extract the sum of the absolute values of the responses, he descriptor for the sub square is the sum of the x derivatives over its four quadrants, sum of the absolute values of the x derivatives and similarly for y. The total descriptor is 4 values per subgrid for a total of 64 values. (16x4) The 4×4 sub-region division responses dx and dy are summed up over each subregion and form a first set of entries to the feature vector 64-dimensional features uses box filters to approximate the derivatives and integrals used in SIFT box filter, which simply averages the pixel values in a K ×K window. This is equivalent to convolving the image with a kernel of all ones and then scaling Each element of the integral image contains the sum of all pixels located on the up-left region of the original image (in relation to the element’s position). This allows to compute sum of rectangular areas in the image, at any position or scale, using only four lookups: Turns out if you wish to determine the sum of pixels in any rectangular portion of an image, there is a very efficient way to do it
\[sum = A-B-C+D A - (C-D) - (B-D) - D = A-B-C+D\]Only have to build the integral image once for an input image Integral image gets bigger as you go down to the right Rectangle filters (Haar wavelet). coefficient 1 and -1, dot product with the pixels that lie underneath them. Get one real-valued thing back \sum (pixels in white area}) - sum (pixels in black area) Weak features individually Build an integral image (Summed area table). Look at pixel (x,y), the value at pixel (x,y) is the sum of all of the pixels to the left and up from (x,y). Intermediate computation is fast to compute. Use dynamic programming (caching intermediate results): value above, and the sum of all the pixels up to you in your particular row The integral image computes a value at each pixel (x,y) that is the sum of the pixel values above and to the left of (x,y), inclusive Continue in scanline order, fast to compute the integral image We can use the integral image to compute the features Shape Context Paper, Belongie & Malik, ICCV 2001 How would you form a descriptor for a shape, not for a keypoint? Designed for Object recognition and digit recognition (image classification) Some descriptors are extremely AD-HOC, some person just came up with some random idea, and found that it worked better than other methods at the time Engineered/hand-crafted feature Doesn’t have the strong mathematical derivation that we saw for other methods, like the Harris Corner Detector. True for SIFT also What is disadvantage of SIFT? Basic invariances e.g. to translation, scale and small amount of rotation must be obtained by suitable pre-processing (rotating and scaling patches), not built into the algorithm or theory Distance between two point sets
- a set of points sampled from the contours on the object. Clear outline between the object, which we call foreground object, and the background object. Could use edge detector Consider the set of vectors originating from a point to all other sample points on a shape. These vectors express the configuration of the entire shape relative to the reference point. distribution over relative positions as a more robust and compact, yet highly discriminative descriptor. Polar coordinate system radius, angle two-dimensional coordinate system in which each point on a plane is determined by a distance from a reference point and an angle from a reference direction. What is log-polar coordinates? coordinate system in two dimensions, where a point is identified by two numbers, one for the logarithm of the distance to a certain point, and one for an angle Log-polar histogram binning? Use reference point as an origin Simply count the number of points that fall into each bin Below, see 3 examples of what this descriptor looks like use 5 bins for (log r) and 12 bins for (theta). 2d histogram. Can flatten into 12*5 = 60-dimensional vector Stored prototype shapes. Capture global shape
Deep Learned Feature Descriptors – learn the weights/filters from data
Learned Invariant Feature Transform (LIFT)
3 networks for detection, orientation, description. Trained separately For matching patches, not full images training the Descriptor first n used to train the Orientation Estimator Rotate patch according to the estimated patch orientation theta d finally the Detector, based on the already learned Descriptor and Orientation Estimator (conditioned on the other two) How does the soft argmax work? [12] from LIFT This allows us to tune the Orientation Estimator for the Descriptor, and the Detector for the other two components Correct matches recovered by each method are shown in green lines and the descriptor support regions with red circles River scene, two stuffed animals, two skulls disturbing
SuperPoint – build dataset, what is homographic adaptation
output a semi-dense grid of descriptors (e.g., one every 8 pixels) MagicPoint Net The notion of interest point detection is semantically ill-defined. create a large dataset of pseudo-ground truth interest point locations in real images, supervised by the interest point detector itself, rather than a large-scale human annotation effort simple geometric shapes with no ambiguity in the interest point locations (Checkerboard grids, f quadrilaterals, triangles, lines and ellipses, Y-junctions, L-junctions, T-junctions as well as centers of tiny ellipses and end points of line segments.) The MagicPoint detector performs very well on Synthetic Shapes, but does it generalize to real images? yes, but not as well as authors hoped Automatically label images from a target, unlabeled domain. Homographic Adaptation The generated labels are used to (c) train a fully-convolutional network that jointly extracts interest points and descriptors from an image Two images of the same planar surface in space are related by a homography. 3x3 matrix you can use to move from pixel coordinates to pixel coordinates in another image The thing you are looking at is flat Both images are viewing the same plane from a different angle Move to a different viewpoint SuperPoint Net Take in unlabeled image and base detector Sample a random homography, warp images, apply detector, get point response, unwarp heatmaps, then aggregate all heatmaps, get interest point superset
D2Net
Tensor viewed as descriptors and detector maps
Matching
Establish some preliminary feature matches between these images he feature descriptors have been designed so that Euclidean (vector magnitude) distances in feature space can be directly used for ranking potential matches The simplest way to find all corresponding feature points is to compare all features against all other features in each pair of potentially matching images A better approach is to devise an indexing structure, much like an index you find at the back of a textbook or book, that allows you to efficient find items Like index in a back of a book. Book: find all pages on which a word occurs (index) We will need some sense of accuracy for matching. Here are 4 useful metrics for evaluating predictions in machine learning: TP: true positives, i.e., number of correct matches; FN: false negatives, matches that were not correctly detected; FP: false positives, proposed matches that are incorrect; TN: true negatives, non-matches that were correctly rejected.
For extremely large databases (millions of images or more), even more efficient structures based on ideas from document retrieval (e.g., vocabulary trees, KD trees, divide the multidimensional feature space along alternating axis-aligned hyperplanes, choosing the threshold along each axis so as to maximize some criterion
SIFT Descriptor Nearest Neighbor Distance Ratio:
If you have many closeby features, then this is a bad feature! will likely be a number of other false matches within similar distances due to the (high dimensionality of the feature space – Many high dimensional vector distances tend to a constant.) PDF Two axes: In a more precise sense, the PDF is used to specify the probability of the random variable falling within a particular range of values, Probability density With 100 samples, count how often they fall into these bins Then normalize by dividing by one Look at only the false positives
Look at only the true positives
second-closest match as providing an estimate of the density of false matches within this portion of the feature space There is a lot to unpack in this plot. The Ratio Test (Lowe, 2004) is an effective method for discarding incorrect SIFT descriptor matches but does not appear to be used in practice for CNN-trained descriptors. The Ratio Test discards nearest-neighbor matches if the ratio of distances to the first and second-nearest neighbors, known as the nearest neighbor distance ratio (NNDR), is greater than a specific threshold, usually 0.8. Intuitively, this means that the closest neighbor will be 4 units away, and 2nd closest was 10 units away, you are in good shape However, if the closest neighbor is 9 units away, and second closest neighbor is 10 units away, then (Lowe, 2004) discovered that the NNDR probability density function (pdf) for true matches is centered at a much lower ratio than the pdf for false matches. In fact, the two pdfs are essentially disjoint, with a threshold of 0.8 providing the separating point. Lowe provides the intuition that many equally-distant nearest neighbor matches in a feature space are symptomatic of (1) matching with background clutter patches or (2) an undetected keypoint in one of the images from the pair to be matched Questions to ask the students What are the strengths of these descriptors What are its weaknesses How is the SIFT feature computed How might you design a patch-based feature that is rotation or scale invariant We can define this nearest neighbor distance ratio (Mikolajczyk and Schmid 2005) a Once we have some hypothetical (putative) matches, we can often use geometric alignment (Section 6.1) to verify which matches are inliers and which ones are outliers.
OpenCV’s SIFT C++ implementation (optimized for SIMD instructions) can be found here. We select the number of image octaves, build a Gaussian pyramid, build Difference of Gaussians pyramid, find the scale space extrema (keypoints), and then compute descriptors for each keypoint.
void SIFT_Impl::detectAndCompute(InputArray _image, InputArray _mask,
std::vector<KeyPoint>& keypoints,
OutputArray _descriptors,
bool useProvidedKeypoints)
{
Mat base = createInitialImage(image, firstOctave < 0, (float)sigma);
std::vector<Mat> gpyr;
int nOctaves = actualNOctaves > 0 ? actualNOctaves : cvRound(std::log( (double)std::min( base.cols, base.rows ) ) / std::log(2.) - 2) - firstOctave;
buildGaussianPyramid(base, gpyr, nOctaves);
std::vector<Mat> dogpyr;
buildDoGPyramid(gpyr, dogpyr);
findScaleSpaceExtrema(gpyr, dogpyr, keypoints);
int dsize = descriptorSize();
_descriptors.create((int)keypoints.size(), dsize, CV_32F);
Mat descriptors = _descriptors.getMat();
calcDescriptors(gpyr, keypoints, descriptors, nOctaveLayers, firstOctave);
}
We can compute the descriptor for each keypoint in parallel. OpenCV uses a parallel for-loop:
static void calcDescriptors(const std::vector<Mat>& gpyr, const std::vector<KeyPoint>& keypoints,
Mat& descriptors, int nOctaveLayers, int firstOctave )
{
parallel_for_(Range(0, static_cast<int>(keypoints.size())), calcDescriptorsComputer(gpyr, keypoints, descriptors, nOctaveLayers, firstOctave));
}
The descriptor size is 128:
// default width of descriptor histogram array
static const int SIFT_DESCR_WIDTH = 4;
// default number of bins per histogram in descriptor array
static const int SIFT_DESCR_HIST_BINS = 8;
int SIFT_Impl::descriptorSize() const
{
return SIFT_DESCR_WIDTH*SIFT_DESCR_WIDTH*SIFT_DESCR_HIST_BINS;
}
class calcDescriptorsComputer : public ParallelLoopBody
{
public:
calcDescriptorsComputer(const std::vector<Mat>& _gpyr,
const std::vector<KeyPoint>& _keypoints,
Mat& _descriptors,
int _nOctaveLayers,
int _firstOctave)
: gpyr(_gpyr),
keypoints(_keypoints),
descriptors(_descriptors),
nOctaveLayers(_nOctaveLayers),
firstOctave(_firstOctave) { }
void operator()( const cv::Range& range ) const CV_OVERRIDE
{
const int begin = range.start;
const int end = range.end;
static const int d = SIFT_DESCR_WIDTH, n = SIFT_DESCR_HIST_BINS;
for ( int i = begin; i<end; i++ )
{
KeyPoint kpt = keypoints[i];
int octave, layer;
float scale;
unpackOctave(kpt, octave, layer, scale);
CV_Assert(octave >= firstOctave && layer <= nOctaveLayers+2);
float size=kpt.size*scale;
Point2f ptf(kpt.pt.x*scale, kpt.pt.y*scale);
const Mat& img = gpyr[(octave - firstOctave)*(nOctaveLayers + 3) + layer];
float angle = 360.f - kpt.angle;
if(std::abs(angle - 360.f) < FLT_EPSILON)
angle = 0.f;
calcSIFTDescriptor(img, ptf, angle, size*0.5f, d, n, descriptors.ptr<float>((int)i));
}
}
private:
const std::vector<Mat>& gpyr;
const std::vector<KeyPoint>& keypoints;
Mat& descriptors;
int nOctaveLayers;
int firstOctave;
};
Now we’ll walk through the descriptor computation. Note that the 3rd argument is the keypoint’s orientation (angle).
static void calcSIFTDescriptor( const Mat& img, Point2f ptf, float ori, float scl,
int d, int n, float* dst )
{
Point pt(cvRound(ptf.x), cvRound(ptf.y));
float cos_t = cosf(ori*(float)(CV_PI/180));
float sin_t = sinf(ori*(float)(CV_PI/180));
float bins_per_rad = n / 360.f;
float exp_scale = -1.f/(d * d * 0.5f);
float hist_width = SIFT_DESCR_SCL_FCTR * scl;
int radius = cvRound(hist_width * 1.4142135623730951f * (d + 1) * 0.5f);
// Clip the radius to the diagonal of the image to avoid autobuffer too large exception
radius = std::min(radius, (int) sqrt(((double) img.cols)*img.cols + ((double) img.rows)*img.rows));
cos_t /= hist_width;
sin_t /= hist_width;
int i, j, k, len = (radius*2+1)*(radius*2+1), histlen = (d+2)*(d+2)*(n+2);
int rows = img.rows, cols = img.cols;
AutoBuffer<float> buf(len*6 + histlen);
float *X = buf.data(), *Y = X + len, *Mag = Y, *Ori = Mag + len, *W = Ori + len;
float *RBin = W + len, *CBin = RBin + len, *hist = CBin + len;
for( i = 0; i < d+2; i++ )
{
for( j = 0; j < d+2; j++ )
for( k = 0; k < n+2; k++ )
hist[(i*(d+2) + j)*(n+2) + k] = 0.;
}
for( i = -radius, k = 0; i <= radius; i++ )
for( j = -radius; j <= radius; j++ )
{
// Calculate sample's histogram array coords rotated relative to ori.
// Subtract 0.5 so samples that fall e.g. in the center of row 1 (i.e.
// r_rot = 1.5) have full weight placed in row 1 after interpolation.
float c_rot = j * cos_t - i * sin_t;
float r_rot = j * sin_t + i * cos_t;
float rbin = r_rot + d/2 - 0.5f;
float cbin = c_rot + d/2 - 0.5f;
int r = pt.y + i, c = pt.x + j;
if( rbin > -1 && rbin < d && cbin > -1 && cbin < d &&
r > 0 && r < rows - 1 && c > 0 && c < cols - 1 )
{
float dx = (float)(img.at<sift_wt>(r, c+1) - img.at<sift_wt>(r, c-1));
float dy = (float)(img.at<sift_wt>(r-1, c) - img.at<sift_wt>(r+1, c));
X[k] = dx; Y[k] = dy; RBin[k] = rbin; CBin[k] = cbin;
W[k] = (c_rot * c_rot + r_rot * r_rot)*exp_scale;
k++;
}
}
len = k;
cv::hal::fastAtan2(Y, X, Ori, len, true);
cv::hal::magnitude32f(X, Y, Mag, len);
cv::hal::exp32f(W, W, len);
k = 0;
for( ; k < len; k++ )
{
float rbin = RBin[k], cbin = CBin[k];
float obin = (Ori[k] - ori)*bins_per_rad;
float mag = Mag[k]*W[k];
int r0 = cvFloor( rbin );
int c0 = cvFloor( cbin );
int o0 = cvFloor( obin );
rbin -= r0;
cbin -= c0;
obin -= o0;
if( o0 < 0 )
o0 += n;
if( o0 >= n )
o0 -= n;
// histogram update using tri-linear interpolation
float v_r1 = mag*rbin, v_r0 = mag - v_r1;
float v_rc11 = v_r1*cbin, v_rc10 = v_r1 - v_rc11;
float v_rc01 = v_r0*cbin, v_rc00 = v_r0 - v_rc01;
float v_rco111 = v_rc11*obin, v_rco110 = v_rc11 - v_rco111;
float v_rco101 = v_rc10*obin, v_rco100 = v_rc10 - v_rco101;
float v_rco011 = v_rc01*obin, v_rco010 = v_rc01 - v_rco011;
float v_rco001 = v_rc00*obin, v_rco000 = v_rc00 - v_rco001;
int idx = ((r0+1)*(d+2) + c0+1)*(n+2) + o0;
hist[idx] += v_rco000;
hist[idx+1] += v_rco001;
hist[idx+(n+2)] += v_rco010;
hist[idx+(n+3)] += v_rco011;
hist[idx+(d+2)*(n+2)] += v_rco100;
hist[idx+(d+2)*(n+2)+1] += v_rco101;
hist[idx+(d+3)*(n+2)] += v_rco110;
hist[idx+(d+3)*(n+2)+1] += v_rco111;
}
// finalize histogram, since the orientation histograms are circular
for( i = 0; i < d; i++ )
for( j = 0; j < d; j++ )
{
int idx = ((i+1)*(d+2) + (j+1))*(n+2);
hist[idx] += hist[idx+n];
hist[idx+1] += hist[idx+n+1];
for( k = 0; k < n; k++ )
dst[(i*d + j)*n + k] = hist[idx+k];
}
// copy histogram to the descriptor,
// apply hysteresis thresholding
// and scale the result, so that it can be easily converted
// to byte array
float nrm2 = 0;
len = d*d*n;
k = 0;
for( ; k < len; k++ )
nrm2 += dst[k]*dst[k];
float thr = std::sqrt(nrm2)*SIFT_DESCR_MAG_THR;
i = 0, nrm2 = 0;
for( ; i < len; i++ )
{
float val = std::min(dst[i], thr);
dst[i] = val;
nrm2 += val*val;
}
nrm2 = SIFT_INT_DESCR_FCTR/std::max(std::sqrt(nrm2), FLT_EPSILON);
#if 1
k = 0;
for( ; k < len; k++ )
{
dst[k] = saturate_cast<uchar>(dst[k]*nrm2);
}
Soft Argmax
Given logits [0.1, 0.7, 0.05, 0.15], where the hard argmax would be 1, the soft argmax delivers 1.007 (as shown below). This float cannot be used as a hard index (i.e. integer), but fortunately the STN not need an integer to extract the patch.
import numpy as np
y = np.arange(4)
S = np.array([0.1,0.7, 0.05, 0.15])
result = np.sum( np.exp(S * 10) * y)
result / np.sum( np.exp(S * 10))
1.007140612556097
LIFT [2] passes this subpixel keypoint localization to a STN.
Spatial Transformer Network
https://pytorch.org/tutorials/intermediate/spatial_transformer_tutorial.html
References
[1]. Moravec
[2]. LIFT: Learned Invariant Feature Transform. PDF.
Sandbox:
Laplacian of Gaussians (Lindeberg (1993; 1998b)/ Difference of Gaussians will skip since we are talking about descriptors Matching Local Self-Similarities across Images and Videos, Shechtman and Irani, 2007 Learning Local Image Descriptors, Winder and Brown, 2007 Comparison of Keypoint Detectors, Tuytelaars Mikolajczyk 2008 FAST, ORB Mikolajczyk and Schmid -> GLOH performed best, followed closely by SIFT Maximally Stable Extremal Regions [Matas ‘02] stable connected component of some gray-level sets of the image . regions which stay nearly the same through a wide range of thresholds The concept can be explained informally as follows. Imagine all possible thresholdings of a gray-level image I. We will refer to the pixels below a threshold as ’black’ and 386 to those above or equal as ’white’. If we were shown a movie of thresholded images It, with frame t corresponding to threshold t, we would see first a white image. Subsequently black spots corresponding to local intensity minima will appear and grow. At some point regions corresponding to two local minima will merge. Finally, the last image will be black. The set of all connected components of all frames of the movie is the set of all maximal regions; Regions whose rate of change of area with respect to the threshold is minimal are defined as maximally stable. – Invariance to affine transformation of image intensities where the relative area change as a function of relative change of threshold is at a local minimum, i.e. the MSER are the parts of the image where local binarization is stable over a large range of thresholds.[1][6]